
Elasticsearch serves in my production system as the secondary storage. Transactional data is ultimately stored in RDS Postgres, but Elasticsearch is employed for its superior query features and performance. And because I have a long-lived growing index, I have experienced growing pains with Elasticsearch (and every other parts of the system, it's a Sisyphean show) that made me look into AWS Elasticsearch Service (AWS ESS) in greater details. I am not covering rolling indices, continuous data flow with an indexing period and retention window, which is another great application of Elasticsearch but not my use case. I have spent more time on this than I should, because a definite answer to ES scalability is complicated. When the official guide from Elastic itself is "it depends", I don't think I have a good shot at coming out being correct.
Unlike Redis, ES can't be scaled effectively with blackbox approach. Each component of ES is scaled differently. Any ES cluster can be explained as following:
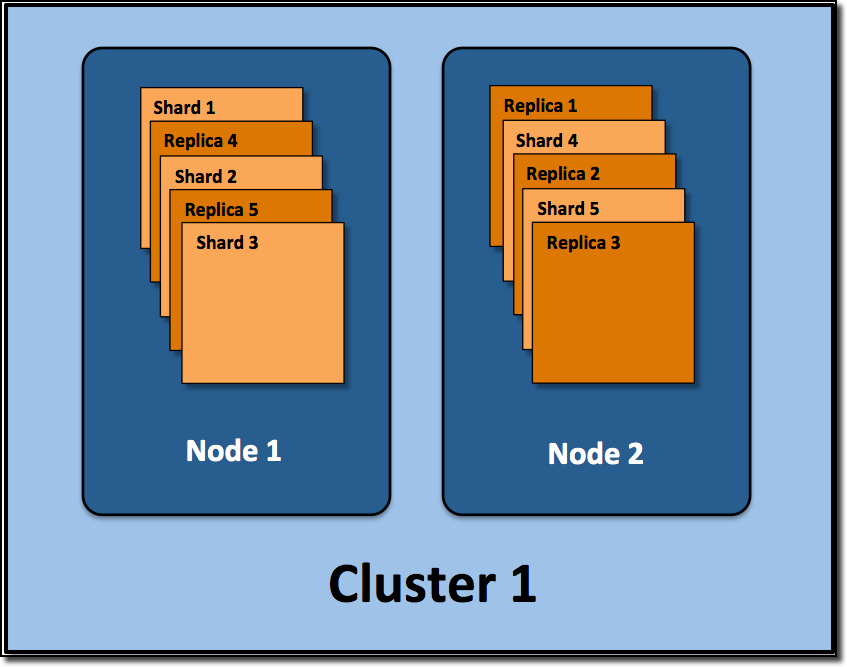 |
| Source: qbox.io |
- Cluster: ES is meant to be run in a cluster. Every instance of AWS ESS is cluster-ready even with only one node.
- Node: A single ES instance. In AWS ESS, each node runs on a separate EC2 instance.
- Index: A collection of documents. Very soon, referring to an ES Index as similar to an SQL database is a bad analogy (read more here). It is the highest level of data organization in ES.
- Shard: Common with other distributed storage system, an index is split into shards and distributed across multiple nodes. ES automatically arranges and balances these shards.
- Replica: A read-only replication of a shard.
I asserted the scalability of AWS ESS from the smallest to the largest elements of a cluster, and the findings are
1. Shard
Scaling on this level involves the size of a shard and the number of shard in a cluster.
AWS's rule of thumb is to keep shard size below 50GB per shard. But that might as well be the upper limit of it. In practice, the best shard size is between 10-30GB in a stable cluster, or 10-20GB when cluster size is subject to frequent change.
The number of shard in a cluster determines maximum size of a cluster and its performance. A node can keep multiple shards, but a shard can't be split further, it has to reside in a single node. If initially a single-node cluster has 10 shards, its maximum growth is 10 nodes, each serving a single shard. The reason people don't create a hundred-shard cluster from day one is that the higher number of shard a cluster has, the more it is taxed on communication between shards. The ideal number of shard is the balance between giving growth space for the dataset and avoid excessive communications between shards. I suggest allocate shards 3-5 times the number of nodes in the initial setup.
2. Replica
In ES, a replica contributes to fail-over, but its primary role is to boost search performance. It takes some of the query load from master shards. Secondly, instead of scanning all nodes in the cluster for a query, the present of replicas allows traversing less nodes while still ensuring all shards are scanned. Push this to an extreme, for n nodes, I can have n shards and n-1 replicas. This means a query never needs to traverse more than one node. However, this also means there is no scale out/in for the cluster, each node has to be big enough for the entire dataset. Not recommended, gotta love the speed though.
3. Node
Scaling node is about choosing the right size for the machine. And this is surprisingly straight forward given ES' nature. ES uses Java, and thus its performance is tied to the mighty JVM. JVM heap size recommendation for ES is 32GB. It (heap size) also can't be more than 50% of available memory. Therefore the ideal memory of an ES instance is 64GB. This is the reason why earlier I suggested a cap of 30GB on shard size, so that the entire shard can fit into memory. A machine with less or more memory is still perfectly functional, it is merely a matter of bang for the buck. I settle on scaling up my machine till 64GB RAM and subsequently scaling out. I still have to deal with a whopping 64GB free memory whenever I scale out (and its bill), so 32GB maybe a more cost-conscious threshold. Meanwhile, I entertain the extra memory with more replicas.
4. Cluster
Scaling a cluster of ES is not simply adding more machines into it, but also understanding the setup's topology. On AWS ESS, the focus on usability dwarfed most ES topology configuration. The only significant configuration left is dedicated master nodes. These nodes perform cluster management tasks and give the data node some slack for stability. AWS guide on this is comprehensible, I couldn't do a better job.
5. AWS ESS drawbacks
It wasn't until the previous point did AWS ESS drawbacks from native ES emerge. In reality, there are more to that. Below is a list of things omitted by AWS ESS.
- ES supports a third type of node: coordinating nodes. These nodes participate in cross-cluster query where a request is first scattered to data nodes and then gathered into a single resultset. Not particular popular in small setup, but completely off the table with ESS.
- There is only HTTP connection. ES supports TCP connection and this should be more favorable for JVM-based languages, receiving better support and cutting down additional network complexity
- No in-place upgrades. Upgrading ES version in AWS ESS is unnecessary painful to do with zero downtime. Painful because it involves launching a new cluster, whitelisting it for reindexing, executing the reindexing and that updating all services to point to the new cluster. Unnecessary because ES comes with in-place / rolling version upgrade.
- Backup frequency is limited. To only one a day. Backup in Elasticsearch is supposed to be pretty cheap.
- Security. One of the biggest reason I haven't provided Kibana as an BI interface to my clients is because X-Pack is not supported.
- Limited access to the rest of ES ecosystem. ES ecosystem is growing fast and a force to be reckoned with. No logs, and no plugins are supported in AWS RSS. Cutting edge much?



